Demystifying Language Models
An introduction to natural language processing and neural networks for Dan O’Sullivan’s Creative Computing course, Interactive Media Arts, NYU. Based on Chapter 11 of Francois Chollet’s Deep Learning with Python.
distilgpt2 running in-browser with Transformers.js
The following text is a very basic overview of how language models are trained, and I hope it can help demystify this genuinely revolutionary technology, and help readers see it for what it really is: massive statistical models that predict the most likely next token. So what is a statistical model? And what do I mean by token? I’ll try to cover the basic concepts in non-technical terms, from artificial neural networks all the way to agents.
Statistical Models
Generally speaking, a lot of people would like to predict the future. And if we could measure everything that exists it might not be so hard to do. The issue is, obviously, that we can’t. So instead of measuring everything and calculating the answer, we have to take a limited sample measurement and make an educated guess.
For example, if you wanted to measure the likelihood of an NYU student’s favorite color, you could ask every single student, or you could ask a sample of students and then generalize their answers onto the entire population of students within a range of certainty.
This, in a nutshell, is statistics. The attempt to quantify how uncertain we are about predictions based on a sample. So a statistical model uses various mathematical techniques to create scaled-down imitations of reality that allow us to make educated guesses, or predictions. This can help describe the relationship between the input and output in terms of uncertainty.
Neural Networks
Neural networks are a type of statistical model in the field of machine learning. Like other models, neural networks also try to estimate the probability of the output based on the input. Neural networks get their name from their shapes, a web of nodes loosely based on the neurons in our brains.
In the models, the interconnected nodes are organized into layers. Each node receives a number of values from the layer before it, performs a calculation, and passes a single output value to all the nodes it is connected to in the next layer. This process goes through each layer and eventually shapes the values of the final layer. In the final layer, each node outputs a value that corresponds to a possible outcome, like a word or category.
Built with p5.js
Training a Model
Notice how while you were playing around with the sketch above, you nudged the value of one node to see if it increased the probability of your target. If it got you closer to your target, you continued increasing, and if not, you decreased it. That is essentially what happens during model training. But instead of nudging one value at a time, the model uses a technique called backpropagation to adjust billions of values in parallel, guided by how much each node affects the target outcome. These adjustments happen over the course of training loops, which means the model’s values are adjusted until the predictions are as accurate as possible.
Now remember, these are statistical models. Since they can’t read all of the sentences ever written, they need a sample of language in order to be able to predict the probability of the next word. This sample is called the training data, and large language models are trained on huge chunks of the internet. The next section will give an overview of how words are processed into numbers that can be calculated by neural networks.
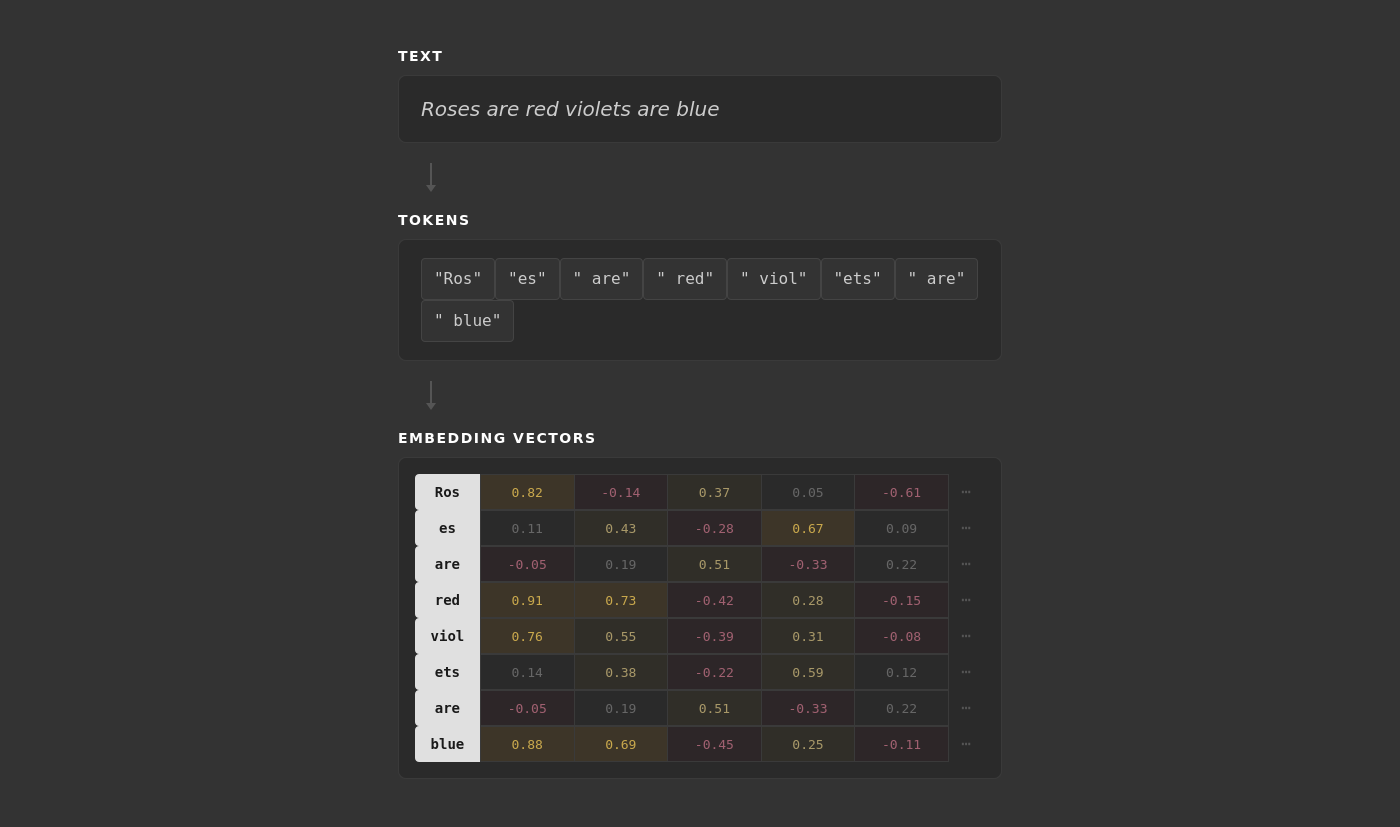
Natural Language Processing
So far we’ve touched on the definition of statistical models, neural networks, and how they are trained. There is one more piece of the puzzle: how do you translate words into values the neural network can process?
Like in the figure above, words or parts of words are broken into tokens. These tokens are the smallest unit each model will process. Once the text is “tokenized”, each token is assigned a random list of numbers with a fixed length. This list of numbers is also referred to as a vector.
During training, the vectors are also adjusted by measuring how each change affects the final prediction. This creates one of the most fascinating parts of artificial intelligence: a numerical representation of each token’s meaning in relation to other tokens. After enough training loops, words like ‘red’ and ‘blue’ end up with similar vectors not because they are both adjectives, but because they both mean colors. This means that if you take the vector for ‘puppy,’ subtract ‘dog,’ and add ‘cat,’ you get a vector close to ‘kitten.’
From Chatbots to Agents
Modern LLMs can do a lot more than generate text, and it seems like agentic AI can successfully complete additional tasks every day. Surprisingly, the ability to complete these tasks and generate the next token is deeply related. In addition to every word from almost every language, agentic AI is also fine-tuned to generate structured commands in a specific syntax, like <tool_name>parameters</tool_name>. Each tool comes with a plain language description that is included in the model’s instructions.
The program that runs the LLM then parses this output and routes the command to the appropriate application. This way, the model can process the instruction and activate the application based on the same probability-based pattern it uses to predict words, while the chat interface on your computer extends its abilities by running classic programs on its behalf.
Language to Describe Large Language Models
The use of AI is already reshaping economies, politics, and humanity’s relationship to itself and to technology. Jobs are changing, education is being reconsidered, and questions about consciousness are making their way from science fiction and philosophy to the news. Unfortunately, we still haven’t developed an accurate language to describe large language models. Symbolism and metaphors used to describe AI are often rooted in magic or mysticism, and the verbs used to describe its functions are heavily anthropomorphised. While these shorthands try to simplify the mechanics of these models, they end up obscuring how they actually work, making it harder to have a serious conversation about their consequences.